Status: 🔒 This project is complete but currently private.
A public demo is not available at this time.
🎯 Business Context & Goals
- Support universities in making more objective, data-driven recommendations for academic and administrative staff.
- Explore how historical performance and competency data can be translated into recommendation insights.
- Build a robust, interpretable ML pipeline that can be adapted to similar HR/education contexts.
🧩 My Role & Responsibilities
- Led the entire data science lifecycle from problem framing to evaluation and reporting.
- Designed and implemented the preprocessing, modeling, and validation strategy.
- Communicated findings via visualizations and structured notebooks for non-technical stakeholders.
📊 Impact & Outcomes
- Produced a recommendation model with strong accuracy and balanced precision/recall.
- Highlighted which features matter most, helping stakeholders understand drivers of recommendations.
- Delivered a reusable framework that can be extended to other recommendation or ranking problems.
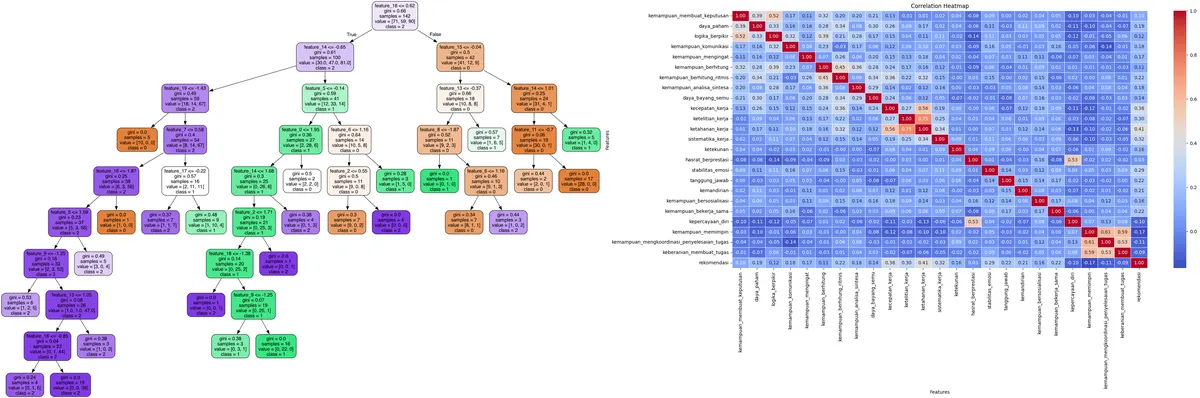
This project is a comprehensive machine learning solution focused on building and evaluating a Random Forest-based classification system for academic staff (dosen) and administrative staff (tendik) recommendations. The solution covers the full data science pipeline, from data preprocessing and feature engineering to model selection, hyperparameter optimization, and interpretability analysis.
Key Features & Technologies
- Data Science & Machine Learning:
- Utilizes Python with libraries such as pandas, scikit-learn, and matplotlib.
- Implements Random Forest classifiers for multi-class recommendation tasks.
- Employs advanced techniques including K-Fold Cross Validation and Grid Search for hyperparameter tuning.
- Conducts ablation studies to analyze the impact of individual features and model parameters on classification performance.
- Visualizes decision trees for model interpretability using Graphviz.
- Data Handling:
- Works with real-world datasets (
dataset_dosen.csvanddataset_tendik.csv) containing dozens of features related to cognitive, social, and professional competencies. - Applies robust preprocessing: missing value handling, categorical-to-numeric conversion, feature scaling, and data splitting.
- Works with real-world datasets (
- Evaluation & Results:
- Achieves high accuracy (up to 88%) and strong precision/recall/F1-scores, demonstrating reliable classification performance.
- Provides detailed evaluation reports and confusion matrices for model assessment.
- Software Engineering:
- Modular Jupyter Notebooks for experimentation, reproducibility, and reporting.
- Well-structured code for easy adaptation to similar classification problems or datasets.
Tech Stack
- Programming Language: Python 3.x
- Data Science Libraries: pandas, numpy, scikit-learn, imbalanced-learn
- Visualization: matplotlib, seaborn, Graphviz
- Development Environment: Jupyter Notebook
- Data Formats: CSV, Excel (XLSX)
- Version Control: Git
Project Outcomes
- Developed a reliable, interpretable recommendation system for academic and administrative staff using Random Forests.
- Identified key features and optimal model parameters through systematic ablation and grid search studies.
- Delivered actionable insights and visualizations to support decision-making in academic environments.
Role: Machine Learning Engineer / Data Scientist / Python Developer
Skills Demonstrated:
- End-to-end machine learning workflow
- Data preprocessing and feature engineering
- Model selection and hyperparameter tuning
- Experimentation and ablation studies
- Data visualization and interpretability
- Reproducible research with Jupyter Notebooks